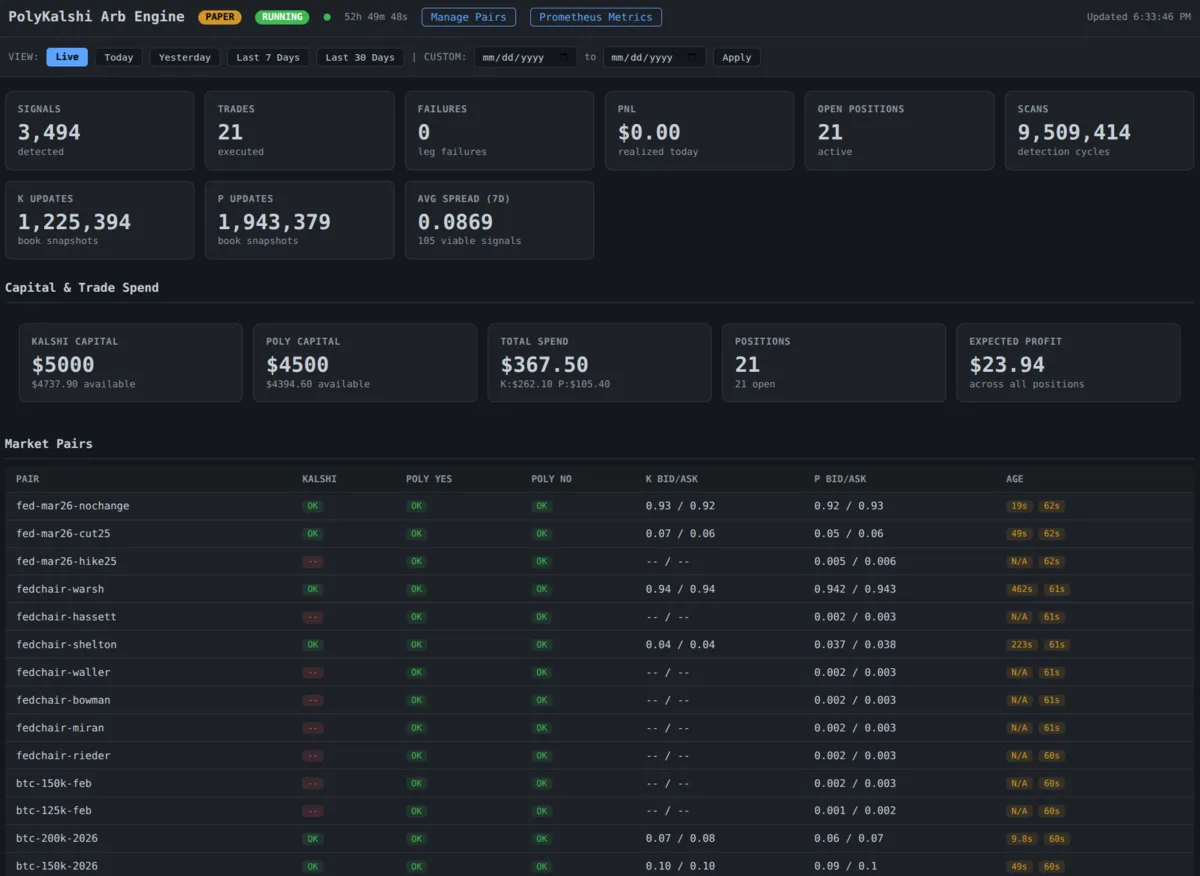
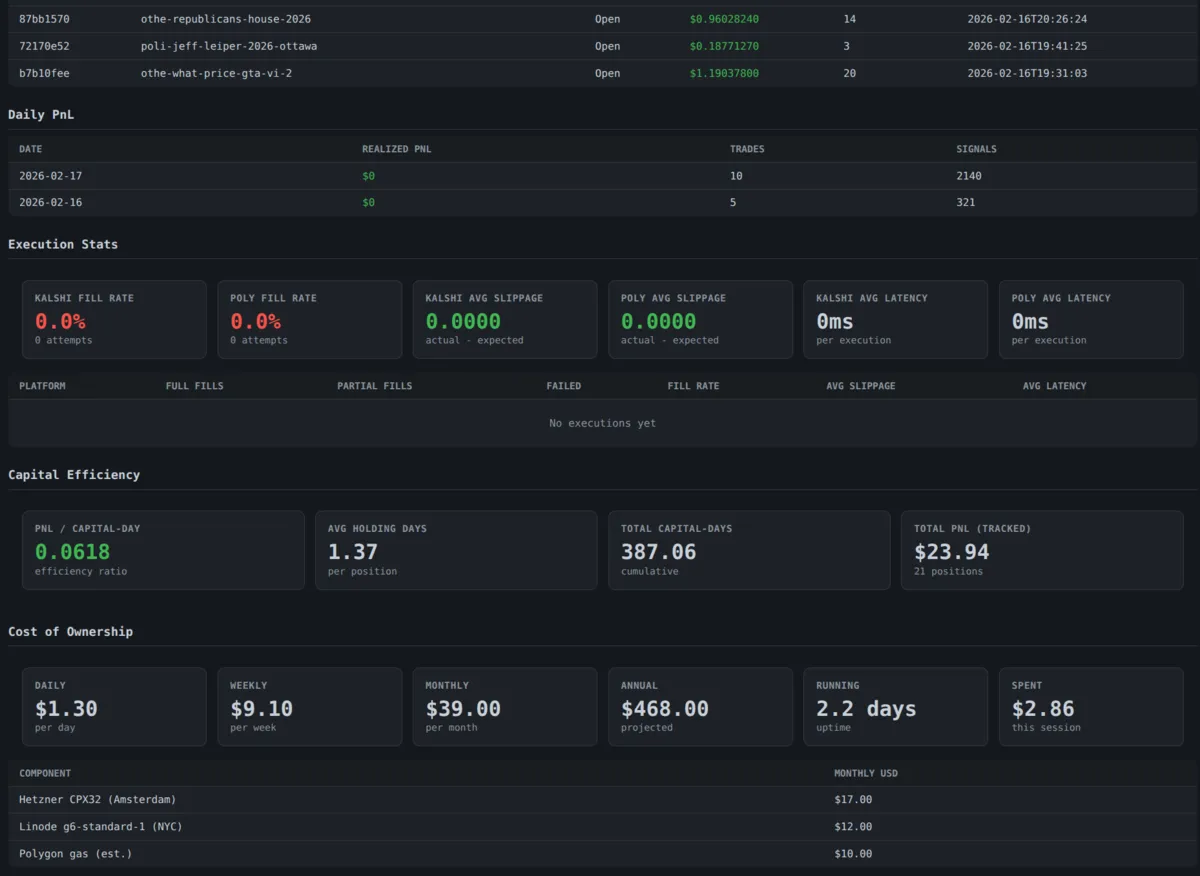
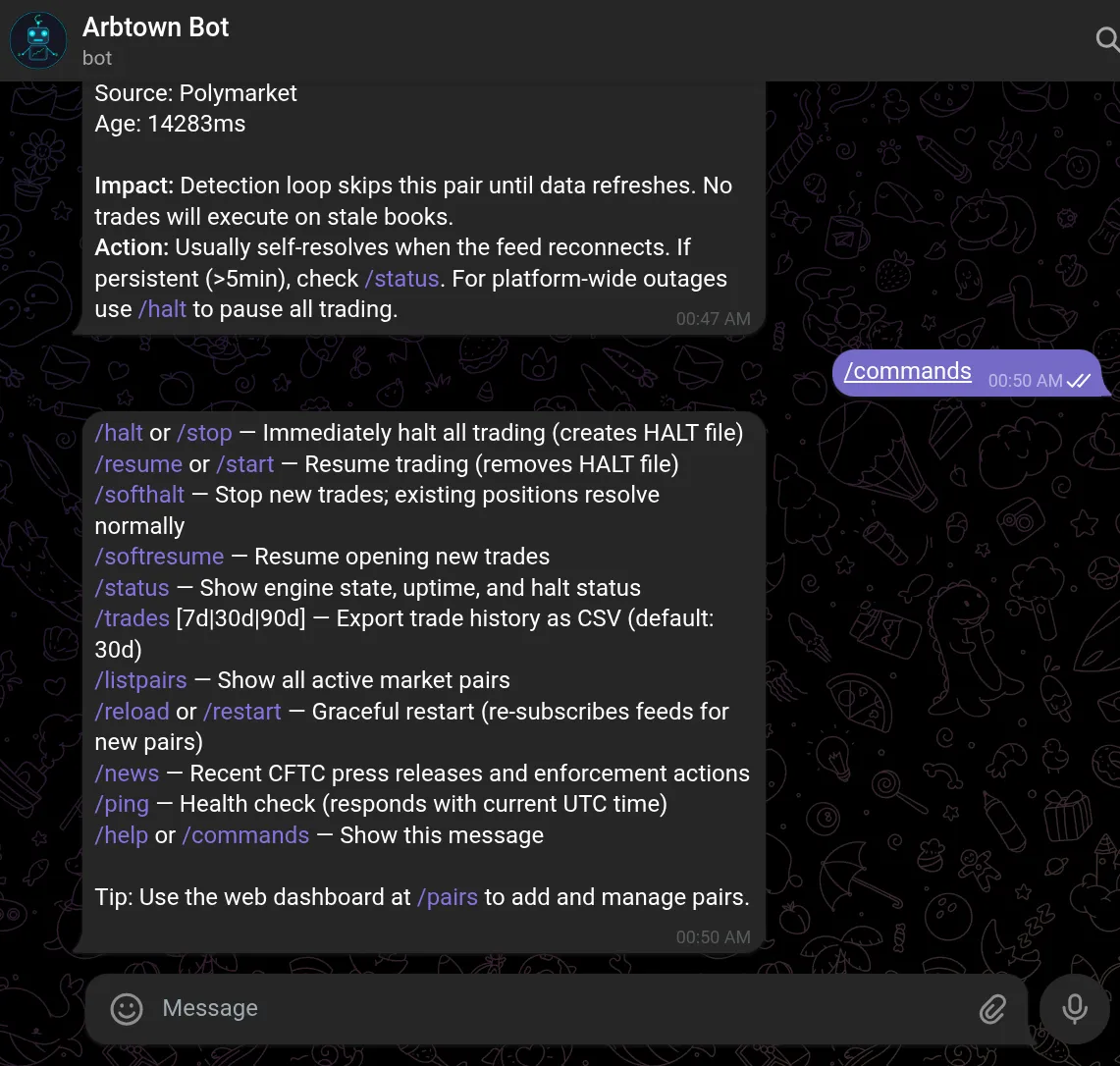
Go Interview
In progressGo Interview is Gong for job seekers: research, record, review, and sharpen every interview so you stop guessing and start closing the right offer.
Most job seekers treat interviews like a test they need to pass. Go Interview treats your job search like what it really is: a sales cycle. Research companies and prepare with intention before you walk in. Record and review your interviews with AI that gives you honest, actionable feedback. Track every company from application to offer. Surface the patterns in how you present, where you stumble, and which roles genuinely align with your skills. Get sharper with every conversation and focus your energy on the opportunities worth winning.
 gointerview.app
gointerview.app
An LLM-powered system that transcribes, scores, and reviews interview recordings to generate structured, actionable feedback across every round of a job search.
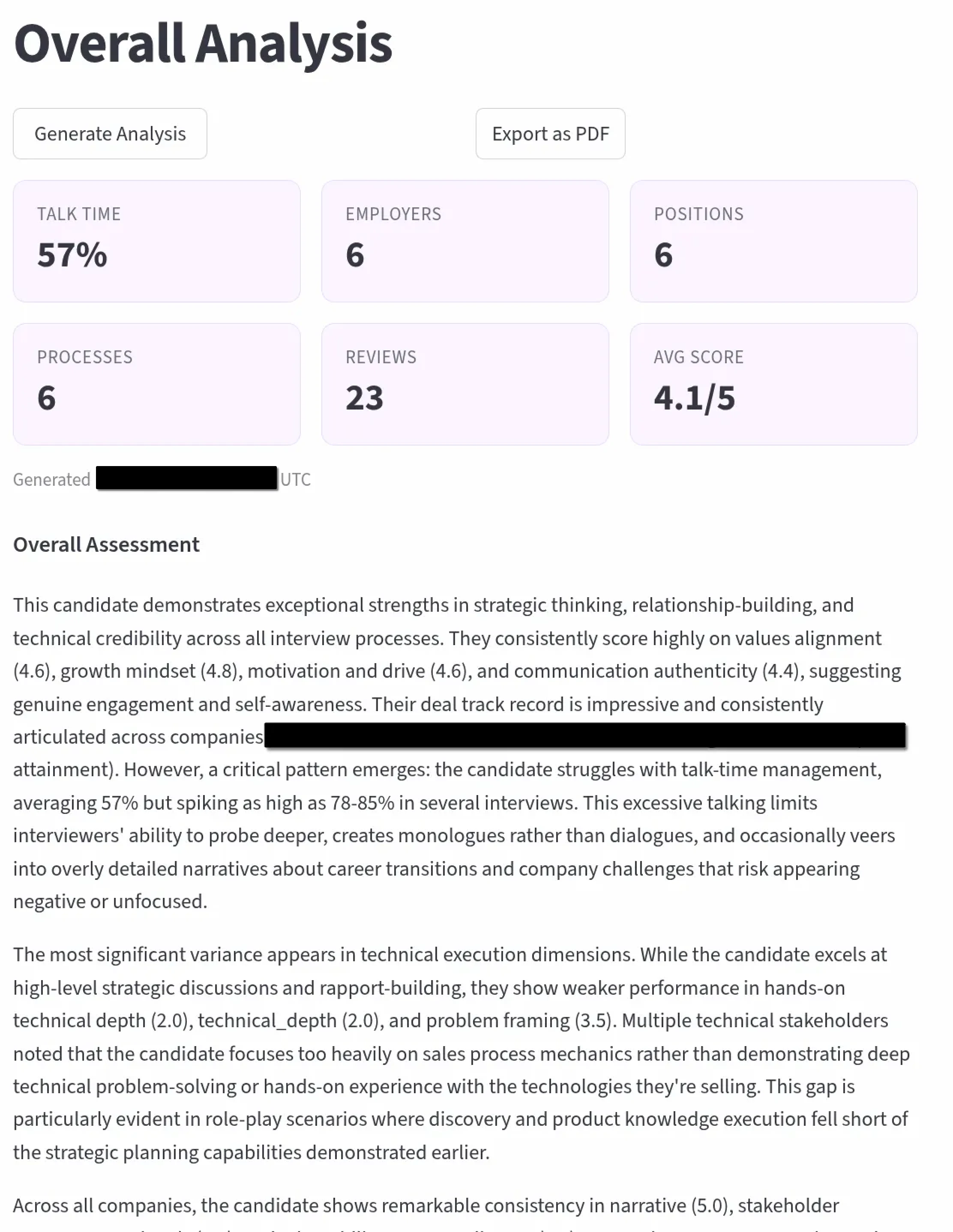
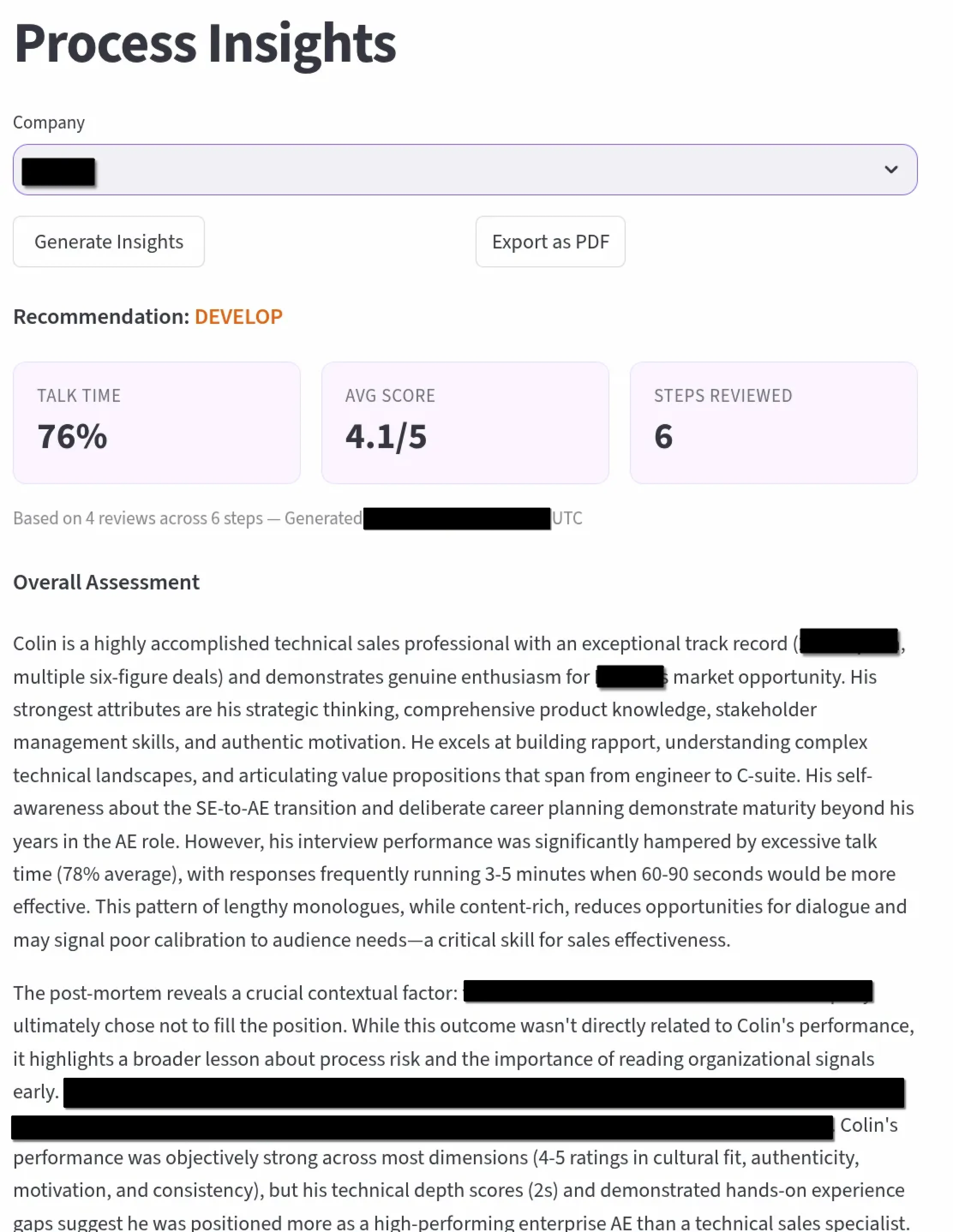
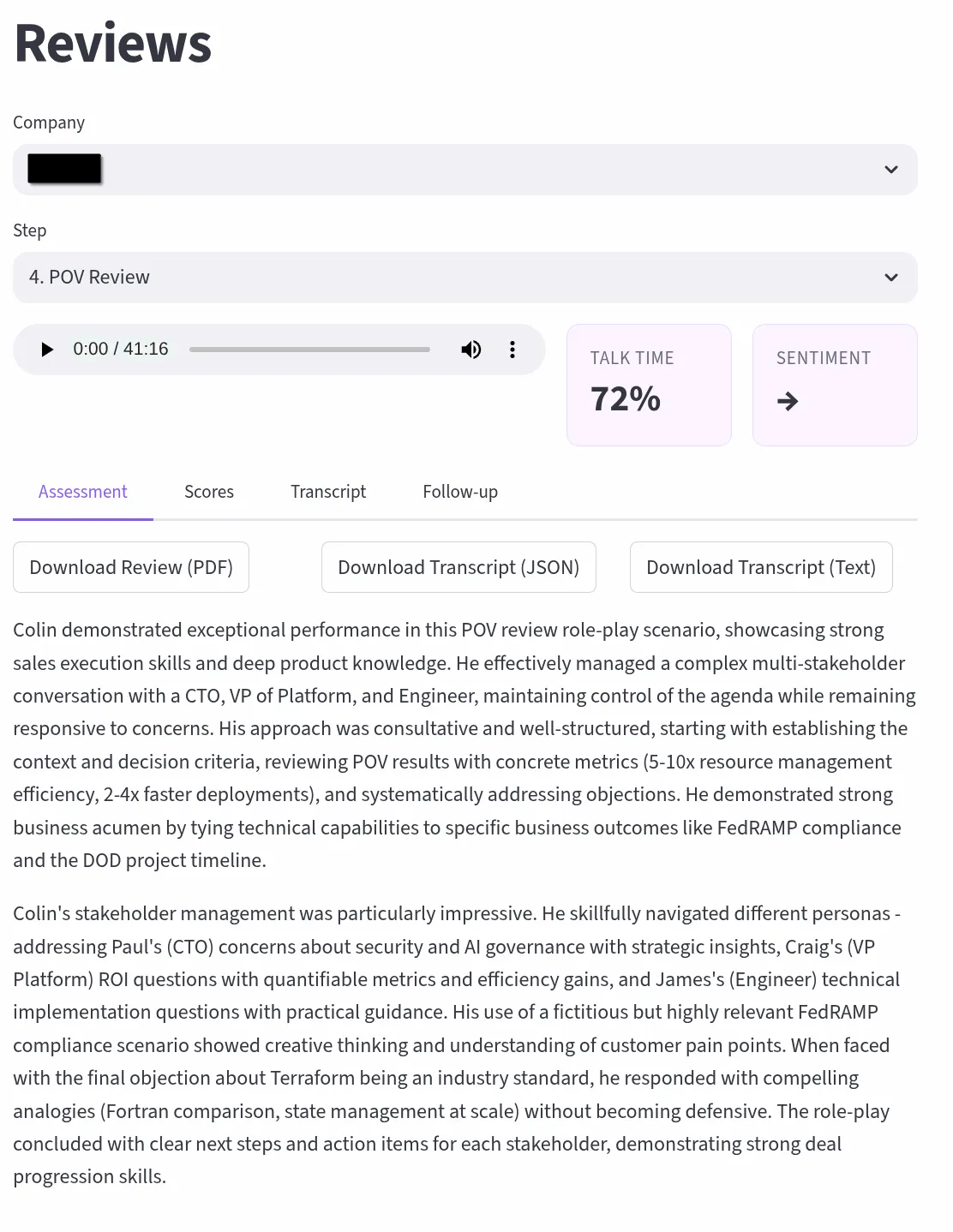
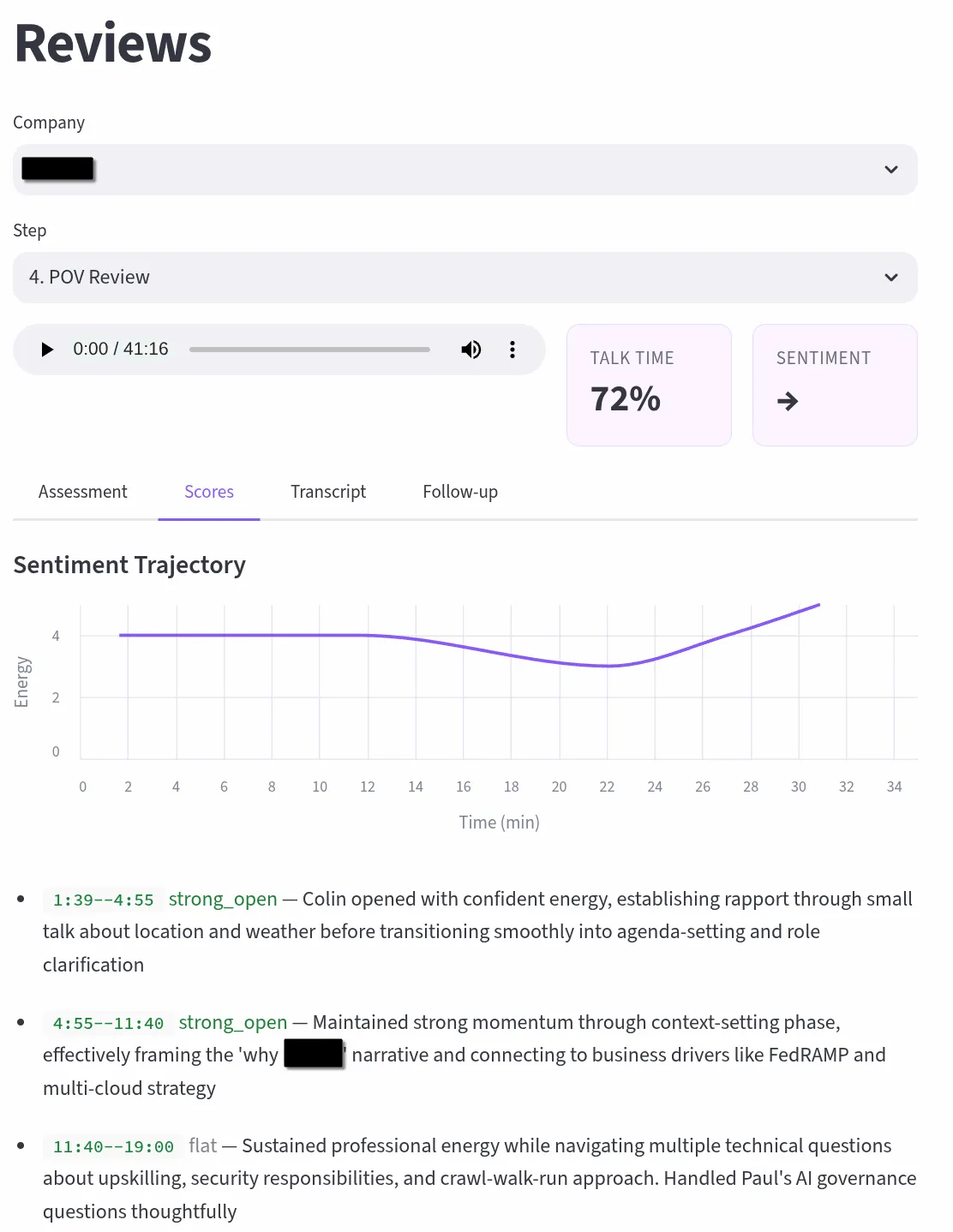
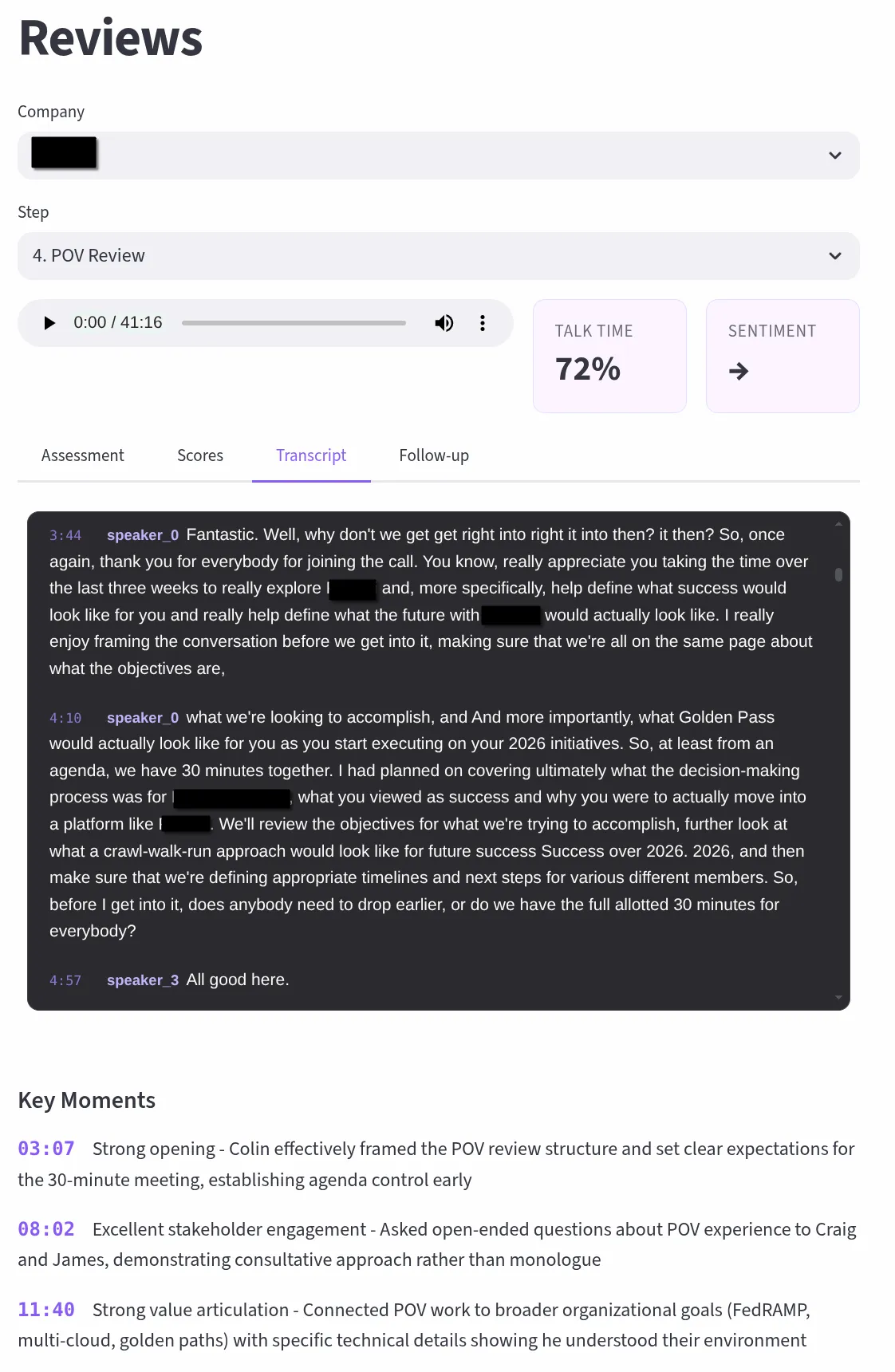
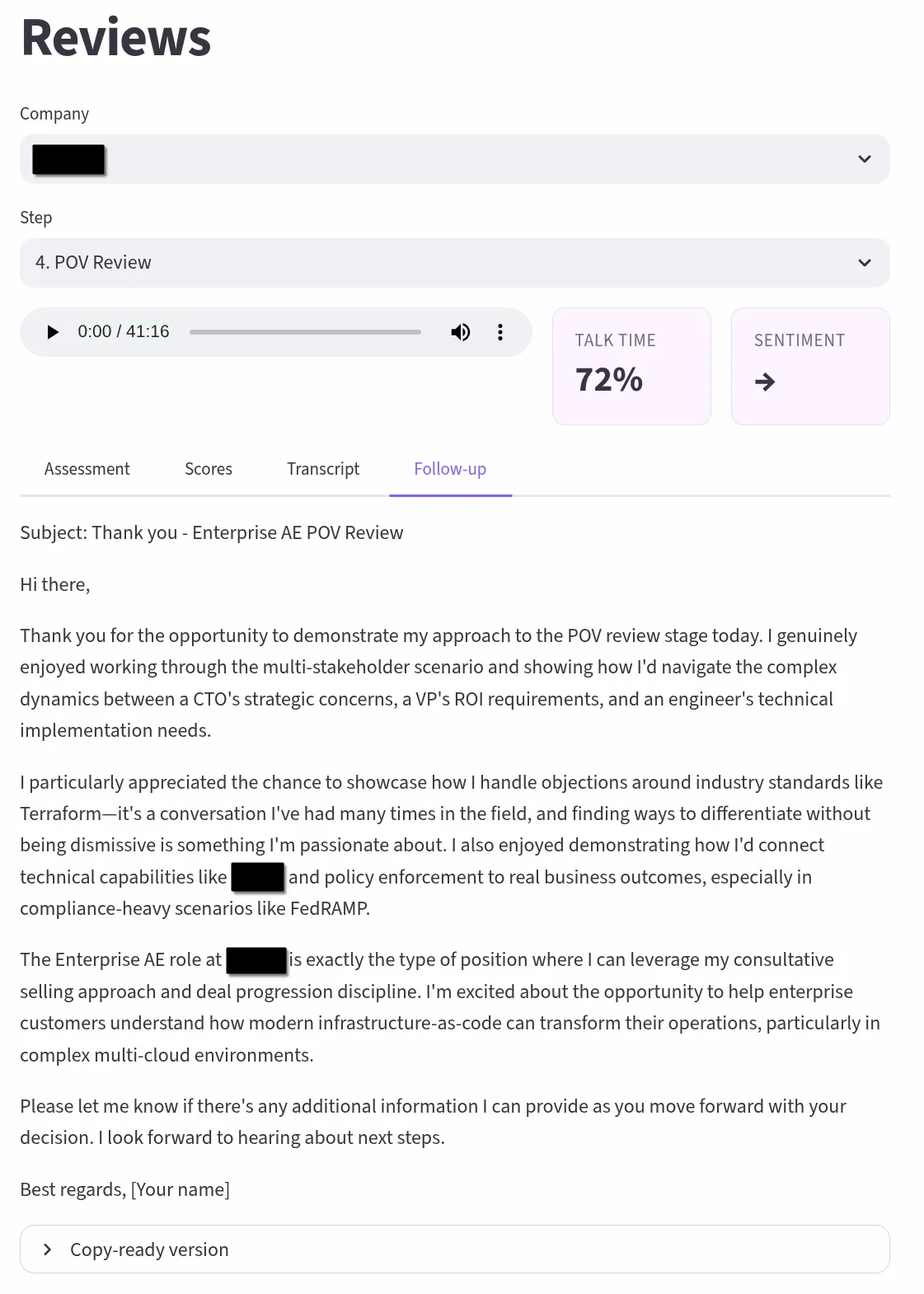
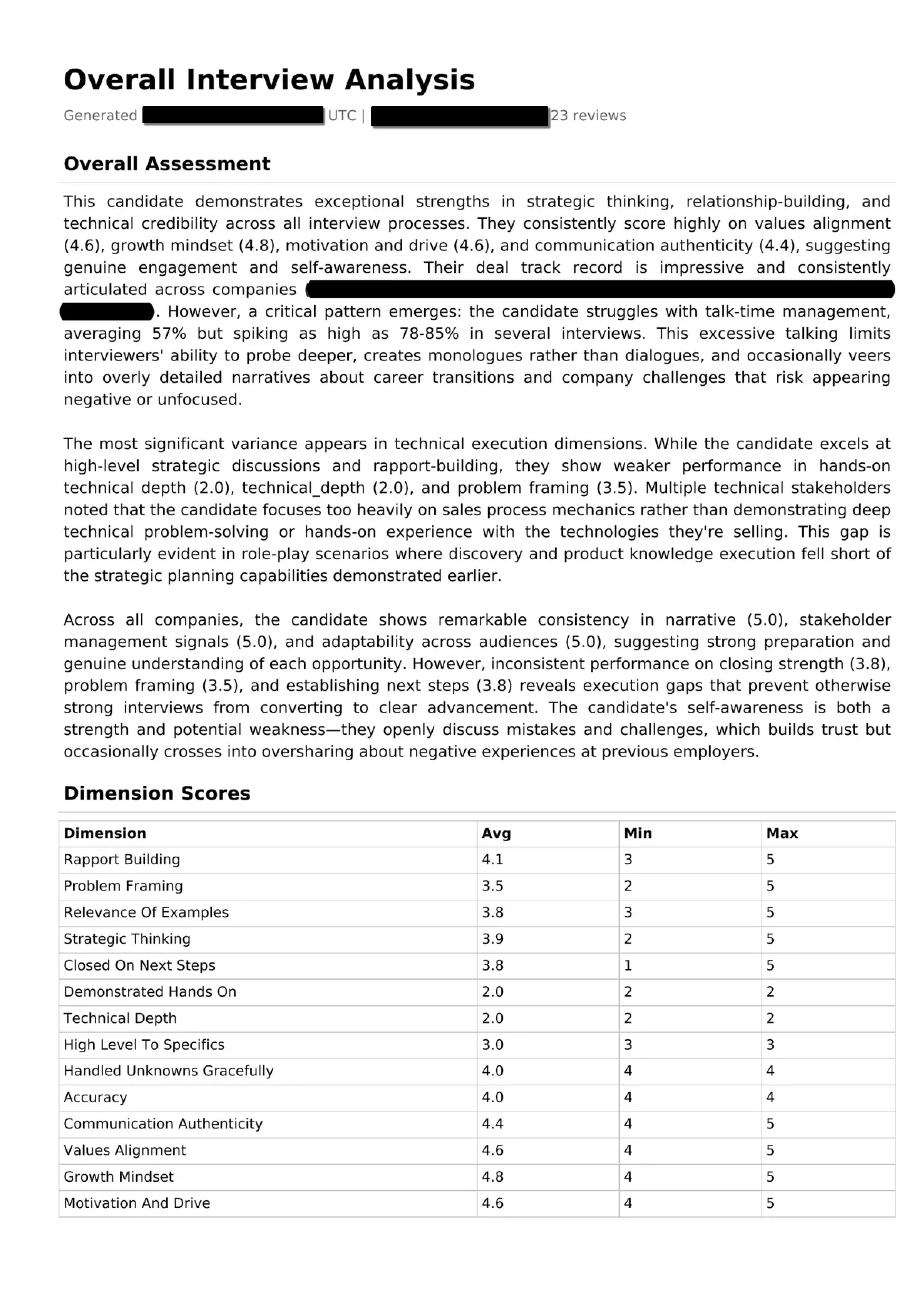
Each interview is scored across configurable dimensions tailored to the round type (recruiter screen, hiring manager, technical deep dive, exec final), with talk-time ratio analysis, sentiment trajectory tracking, and automatic question extraction that builds a searchable bank across all interviews. Transcription runs a dual-path pipeline with NVIDIA Parakeet TDT and NeMo Sortformer on a GCP spot T4 for GPU-accelerated diarized transcription with word-level timestamps. Reviews route through Claude API or locally-hosted Scout, turning every recorded conversation into structured, actionable feedback, identifying exactly where momentum built, where it dipped, and what to adjust for the next round.
Screenshots
Example Reports
First page of each report.
 Page 1
Page 1  Page 1
Page 1 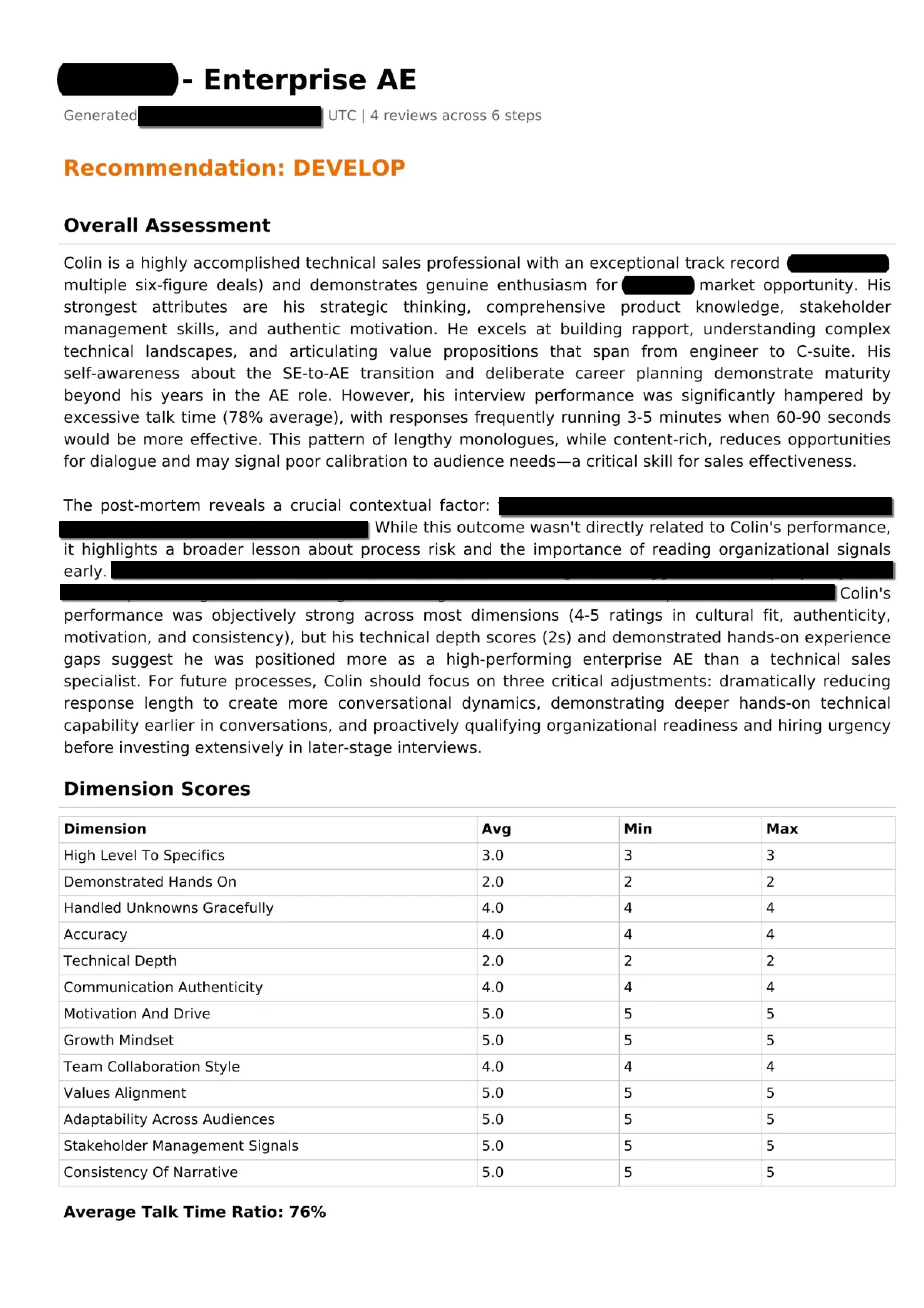 Page 1
Page 1